
브라우저의 주소창에 https://google.com 을 입력하고 엔터를 누르면 당연하게도 구글 홈페이지가 나타난다. 그런데 어떻게?
간략한 순서도
- 브라우저가 URL을 해석한다
- 브라우저의 캐시에 해당 도메인이 캐싱되어 있는지 확인한다. ‼️중요
- DNS(도메인 네임 서버)에 해당 도메인의 IP주소를 요청한다.
- 받아온 IP주소를 기반으로 HTTP request를 만든다.
- 만들어진 request는 네트워크 스택을 통과하며 세그먼트, 패킷, 프레임이 더해진 캡슐화를 한 뒤 서버에 전송한다.
- 서버는 해당 데이터를 역캡슐화하여 request를 확인하고 response를 만들어 동일하게 캡슐화 하여 전송한다.
- 브라우저는 response를 역캡슐화 하여 해당 패킷의 body에 들어있는 HTML파일을 렌더링한다.
도메인네임과 IP주소
- IP: 다양한 NIC(Network Interface Controller)들이 서로를 인식하기 위해 지정받은 식별용 번호이다. 현재는 IPv4 버전(32비트)로 구성되어 있다.(ex: 127.0.0.1) 현재 IPv4 주소의 부족으로 새로 생긴 IPv6의 경우 128비트로 구성되어 있다
// IPv6의 주소 간략화 과정
2001:0DB8:0000:0000:0000:0000:1428:57ab
2001:0DB8:0:0:0:0:1428:57ab
2001:0DB8::::1428:57ab
2001:0DB8::1428:57ab
- Domain Name(도메인 네임): IP주소는 12자리의 숫자로 되어있기 때문에 사람이 외우기 힘들다는 단점이 있다. 그래서 IP주소를 문자로 표현한 주소를 도메인네임 이라고 한다. 도메인네임은 사람의 편의성을 위해 만든 주소이므로 실제로는 컴퓨터가 이해할 수 있는 IP주소로 변환하는 작업이 필요하다. 이때 사용할 수 있도록 미리 도메인 네임과 해당 IP주소값을 한 쌍으로 저장하고 있는 데이터베이스를 DNS(Domain Name System)이라고 부른다.
URL 해석
브라우저는 URL을 파싱한다. URL에는 프로토콜, 도메인, 포트가 지정되어 있다.
Ex: https://google.com:443
https→ 사용할 프로토콜google.com→ 요청할 URL443→ 포트번호
브라우저 캐시 확인
브라우저의 Domain Name System에 해당 도메인과 IP주소가 기록되어 있다면 도메인 네임 서버에 해당 도메인에 대한 IP주소를 요청하지 않고 바로 해당 IP주소에 handshake를 통한 TCPIP연결을 수립한다.
해당 도메인 주소가 기록되어 있지 않다면 도메인 네임 서버에 해당 도메인의 IP주소를 요청한다.
도메인 네임 서버도 또 다시 Root Name Server, Middle Name Server등에 요청하여 주소를 받아온다.
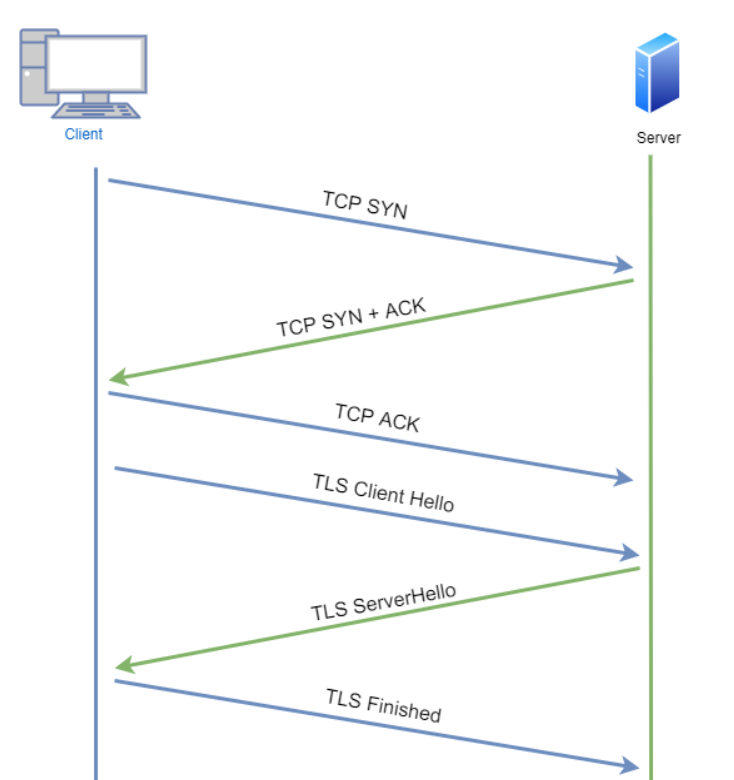
아래의 그림은 서버와 클라이언트간의 handshake가 일어나는 과정이다.
Request 생성 및 캡슐화
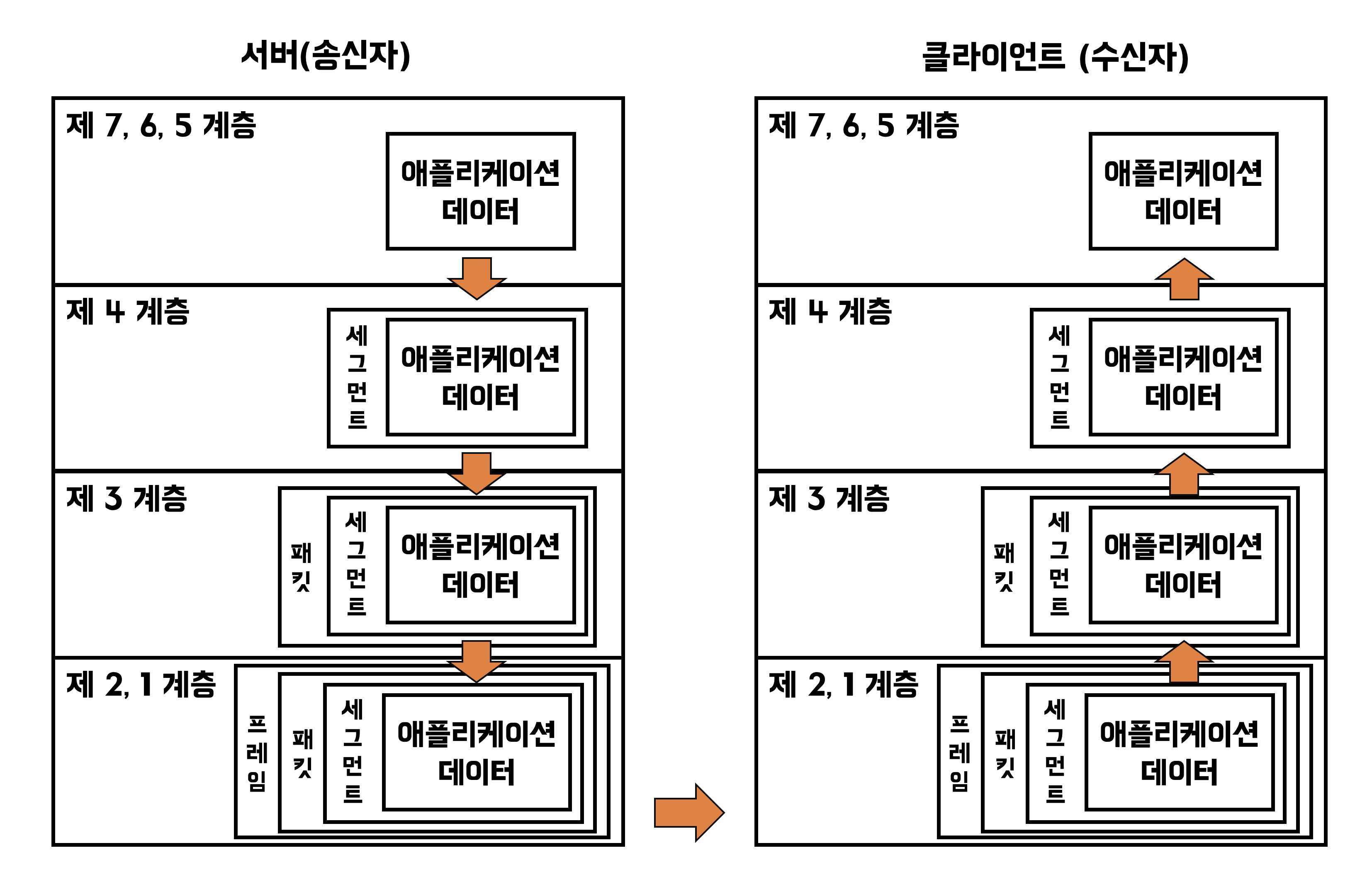
서버는 상위 계층에서 하위 계층으로 캡슐화 처리를 하여 전송용 데이터를 만든다.
- 먼저 서버 애플리케이션으로 만든 애플리케이션 데이터를 그 상태로 전송 계층에 전달한다.
- 전송 계층은 받은 애플리케이션 데이터를 TCP/UDP 캡슐(세그먼트)에 넣어 네트워크 계층으로 전달한다.
- 네트워크 계층은 받은 세그먼트를 IP 캡슐(패킷)에 넣어 데이터링크 계층으로 전달한다.
- 데이터링크 계층은 받은 패킷을 이더넷 캡슐(프레임)에 넣어 물리 계층으로 전달한다.
- 물리 계층은 받은 프레임을 신호로 보내기 좋은 비트로 변환한 후 전기 신호나 광 신호로 만들어 보낸다.
데이터를 수신하는 클라이언트 측이 실행하는 처리가 역캡슐화이다. 클라이언트는 하위 계층에서 상위 계층으로 역캡슐화 처리를 하여 원래의 애플리케이션 데이터로 되돌려 간다.
- 먼저 물리 계층에서 전기 신호나 광 신호를 받으면 비트로 변환한 후 프레임으로 만들어 데이터링크 계층으로 전달한다.
- 데이터링크 계층은 받은 프레임에서 패킷을 꺼내 네트워크 계층으로 전달한다.
- 네트워크 계층은 받은 패킷에서 세그먼트를 꺼내 전송 계층으로 전달한다.
- 전송 계층은 받은 세그먼트에서 데이터를 꺼내 원래의 애플리케이션 데이터를 클라이언트 애플리케이션에게 전달한다.
렌더링
- 다운로드 → 브라우저에 내장된 HTML Loader(로더)가 서버로부터 전달받은 응답의 body에 있는 문서를 읽으면서 정보를 파악한다. 파일의 타입, 데이터 타입, 다운로드 여부 등등 → HTML의 경우 위에서 아래로 읽어 내려간다.(css와 js의 위치가 이때문에 중요)
- DOM Tree 파싱 → 웬 엔진이 가진 HTML/XML Parser 가 문서를 파싱하여 DOM Tree를 만든다.
- CSSOM Tree 파싱 → 외부 css 파일과 함꼐 포함된 스타일 요소를 파싱하여 CSSOM Tree를 만든다. 스타일은 브라우저 자체의 스타일 - 사용자 정의 스타일 - html태그에 작성된 스타일 순서로 처리되며 나중에 처리되는 스타일을 따르게 된다.
- 렌더링 트리 형성 → DOM Tree와 CSSOM Tree를 결합하여 렌더링 트리를 형성한다. 이 때 화면에 드러나지 않는
head태그나display: none;과 같은 요소는 렌더트리에 포함되지 않는다. - 레이아웃 → 기기의 뷰포트 내에서 노드들의 정확한 위치와 크기를 계산한다. 리플로우 과정이라고도 한다.
- 페인팅 → 레이아웃이 끝나면 렌더링 엔진은 페인트 이벤트를 발생시켜 렌더링 트리를 화면에 그린다. 래스터화 과정이라고도 한다.
- 브라우저는 HTML이 전부 파싱될때까지 기다리지 않고 레이아웃과 페인팅 과정을 진행한다. 웹페이지에 접속시 페이지가 한꺼번에 뜨지 않고 점점 화면을 채워나가는 것은 바로 이 때문이다.