
파이썬 공식 문서를 참고하여 작성하였습니다.
알고리즘 - 시간 복잡도와의 싸움
당연하게도 제일 처음 배우고 사용한 언어가 파이썬이다보니 자바스크립트를 꾸준히 공부하면서도 틈틈이 공부하고 푸는 알고리즘 문제들은 전부 파이썬으로 해결했다. 파이썬은 여러가지 자료형을 제공하는데 그 중에는 Set이라는 자료형도 있다. Set은 서로 다른 해시 가능 객체의 순서 없는 컬렉션으로, 파이썬에 기본적으로 내장된 라이브러리 중 하나이며 집합 형 이라고도 한다.
다시 말해 Set에 담기는 자료들은 순서가 존재하지 않으며, 해당 인스턴스 안에 저장된 해시 가능한 자료들은 유일하다(같은 값은 가진 원소가 2개 이상 존재하지 않는다). Set은 교집합, 합집합, 차집합, 대칭 차집합과 같은 수학 연산을 계산할 수 있다.
알고리즘에서 Set은 엄청나게 유용하다. 일련의 과정을 따라 계산된 값들이 들어있는 집합에 특정 원소가 포함되어 있는지 알아야 할 경우 리스트를 사용하면 앞 또는 뒤에서 하나씩 인덱스에 따라 원소들을 검색 해가며 해당 원소가 포함되어 있는지 찾아야 한다. 물론 원소들이 특정 기준(ex: 오름 차순 이나 내림 차순)을 만족할 경우 다른 정렬 알고리즘들을 활용하여 시간 복잡도를 줄일 수 있지만 통상 길이가 N인 리스트에서 특정 원소의 유무 검사에는 O(N)이 걸린다. 그러나 Set을 활용할 경우 무조건 O(1), 즉 상수 시간으로 유무 검사를 해준다.
그러다 하루는 궁금증이 생겼다. 해당 원소가 있는지 알려면 어쨌든 Set도 자신이 가지고 있는 원소들은 뭐가 있는지 찾아봐야 할 텐데… 어떻게 Set에서의 자료 검색은 상수시간이 되는걸까?
해시 테이블?
답은 해시 테이블 이었다. 해시테이블은 연관 배열(Associative array) 구조를 이용하여 키(Key)에 결과 값(value)을 저장하는 자료구조이다. 키와 값은 1:1로 연관되어 있고 키를 사용하여 값을 불러올 수 있다. 해당 키로부터 값을 도출하기 위해 해시함수가 사용된다. 무슨 말인지 말로는 설명이 잘 안되니 그림을 바로 보자.
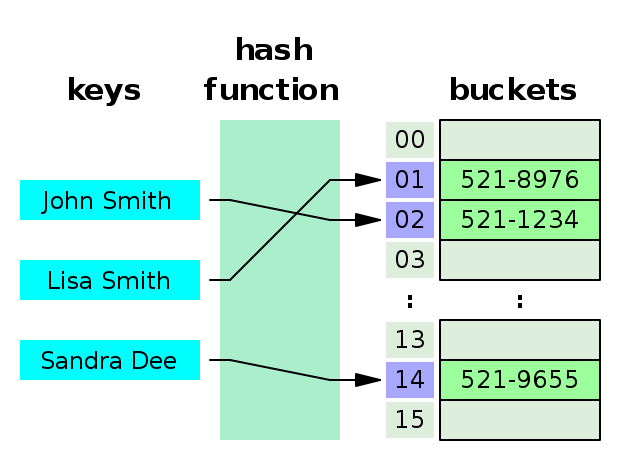
해시 테이블은 크게 키(Key), 값(Value), 해시함수(Hash function), 그리고 저장소(Bucket)으로 이루어져 있다. 키는 해시함수를 거쳐서 해시로 변경이 되며 해시는 값과 매칭되어 저장소에 저장된다. 우리가 사용하는 Set의 경우 가변형으로(add나 remove로 값을 넣고 뺄 수 있음) 해시 값은 존재하지 않는다고 한다. 해시 값을 사용하는 frozenset도 있지만 이것은 불변형이라고 한다.
핵심은, Set에 원소를 저장할때는 기존의 리스트나 어레이처럼 앞, 뒤에 원소를 넣어주는 것이 아니라 해시함수를 거친 해시로 변경하여 저장소에 넣어준다는 것이다. Set은 값이 없다고 했으니 아마 값을 의미하는 부분은 해당 원소가 있는지 없는지만 구분하는 True, False 등으로 표현해주는 것 같다.
이와 같은 방식을 사용하기 때문에 우리가 특정 원소가 해당 Set에 존재하는지를 물어본다면 Set은 저장소의 앞 또는 뒤부터 검사를 시작하지 않는다. 특정원소를 해시함수를 통과 시킨 뒤 해당 해시가 저장소안에 있는지 없는지 검사만 하면 된다. 그렇기에 한번의 연산, O(1)만 일어나면 된다. 와우….
조금 더 찾아보니 해시 테이블의 삽입과 삭제 과정도 O(1)을 만족한다고 한다. 키는 고유하며 해시함수의 결과로 나온 해시와 값을 저장소에 넣기만 하면 되기 때문이다. 삽입의 경우 이론상으로는 O(N)이 나올 수 있다고는 한다. 해시 충돌이 있기 때문인데 서로 다른 키가 해시함수를 통과했을 때 동일한 값이 될 수도 있기 때문이다. 하지만 이는 예전부터 고려되었기에 현재 파이썬의 해시 테이블과 해시함수는 해시 충돌을 방지하기 위한 장치들이 충분히 있으므로 O(1)이라고 믿고 사용해도 좋다고 한다.
실험
그럼 간단하게 실험을 통해 알아보자. 1부터 10,000,000 까지의 숫자를 각각 리스트, Set에 넣고 중간값인 5,000,000 이라는 값이 해당 집합 안에 있는지 물어보면 된다. 내 예상대로라면 리스트 검색의 경우 시간이 꽤나 걸리는 반면 Set은 시간이 거의 걸리지 않을 것이다. 과연?
from time import time
num_list = [i for i in range(1, 10 ** 7)]
num_set = set(i for i in range(1, 10 ** 7))
print('Start analysis')
number = 5 * 10 ** 6
start_time = time()
if number in num_list:
print('number is in num_list: ', end='')
print(time() - start_time)
start_time = time()
if number in num_set:
print('number is in num_set : ', end='')
print(time() - start_time)
결과는 다음과 같다.
Start analysis
number is in num_list: 0.0781099796295166
number is in num_set : 3.0994415283203125e-06
리스트의 경우 7 * 10 ** -2, 즉 0.07초가 걸린 반면 Set은 3 * 10 ** -6, 3마이크로초(…) 가 걸렸다. 1000배 이상 빠르게 확인을 할 수 있었다. elem in list 형태의 검사는 리스트의 맨 앞부터 검사를 하기 때문에 찾고자 하는 원소가 리스트의 앞쪽에 있는 경우에는 시간차이가 없었다. 하지만 원소가 뒤쪽에 위치할수록 시간차이는 극명하게 벌어졌다. (number = 10 ** 7 -3 을 넣어보시라)
오늘은 매일 편리하게 사용하면서도 어떻게 그 기능이 구현되는가에 대한 생각이 들어 Set에 대해 찾아보았다. 해시테이블이 최고다… Set뿐만 아니라 DIctionary의 키 값 또한 해시테이블로 구성된다고 한다. 아마 이 경우에는 딕셔너리의 값이 해시된 키와 같이 저장될 것으로 생각한다. 해시 테이블을 적극 활용하여 풀어볼만한 문제는 프로그래머스 사이트의 전화번호 목록 과 위장이 있다. 시간이 된다면 풀어보시길!